



OpenAI’s recent unveiling of GPT-4o has set the stage for a new era in AI language models and how we interact with them.
The most impressive part was the support of live interaction with ChatGPT with conversational interruptions.
Despite some hiccups during the live demo, I cannot feel other than amazed at what the team has accomplished.
Best of all, right after the demo, OpenAI allowed access to the GPT-4o API.
In this article, I will present my independent analysis measuring the classification abilities of GPT-4o vs. GPT 4 vs. Google’s Gemini and Unicorn models using an English dataset I created.
Which of these models are strongest in English understanding?

What’s New with GPT-4o?
At the forefront is the concept of an Omni model, designed to comprehend and process text, audio, and video seamlessly.
The focus of OpenAI appears to have shifted towards democratizing GPT-4 level intelligence to the masses, making GPT-4 level language model intelligence accessible even to free users.
OpenAI also announced that GPT-4o includes enhanced quality and speed across more than 50 languages, promising a more inclusive and globally accessible AI experience, for a cheaper price.
They also mentioned that paid subscribers would get five times the capacity compared with non-paid users.
Furthermore, they will release a desktop version of ChatGPT to facilitate real-time reasoning across audio, vision, and text interfaces for the masses.
How to use the GPT-4o API
The new GPT-4o model follows the existing chat-completion API from OpenAI, making it backward compatible and simple to use.
from openai import OpenAI
OPENAI_API_KEY = ""
def openai_chat_resolve(response: dict, strip_tokens = None) -> str:
if strip_tokens is None:
strip_tokens = []
if response and response.choices and len(response.choices) > 0:
content = response.choices[0].message.content.strip()
if content is not None or content != '':
if strip_tokens:
for token in strip_tokens:
content = content.replace(token, '')
return content
raise Exception(f'Cannot resolve response: {response}')
def openai_chat_request(prompt: str, model_name: str, temperature=0.0):
message = {'role': 'user', 'content': prompt}
client = OpenAI(api_key=OPENAI_API_KEY)
return client.chat.completions.create(
model=model_name,
messages=[message],
temperature=temperature,
)
response = openai_chat_request(prompt="Hello!", model_name="gpt-4o-2024-05-13")
answer = openai_chat_resolve(response)
print(answer)
GPT-4o is also available using the ChatGPT interface:
Official Evaluation
OpenAI’s blog post includes evaluation scores of known datasets, such as MMLU and HumanEval.

As we can derive from the graph, GPT-4o’s performance can be classified as state-of-the-art in this space — which sounds very promising considering the new model is cheaper and faster.
However, during the last year, I have seen multiple models that claim to have state-of-the-art language performance across known datasets. In reality, some of these models have been partially trained (or overfit) on these open datasets resulting in unrealistic scores on leadboards.
Performance Results
Independent evaluation of the following models:
- GPT-4o: gpt-4o-2024-05-13
- GPT-4: gpt-4-0613
- GPT-4-Turbo: gpt-4-turbo-2024-04-09
- Gemini 1.5 Pro: gemini-1.5-pro-preview-0409
- Gemini 1.0: gemini-1.0-pro-002
- Palm 2 Unicorn: text-unicorn@001
The task given to the language models is to match each sentence in the dataset with the correct topic.
This allows us to calculate an accuracy score per language and each model’s error rate.
Since the models mostly classify correctly, I am plotting the error rate for each model.
Remember that a lower error rate indicates better model performance.
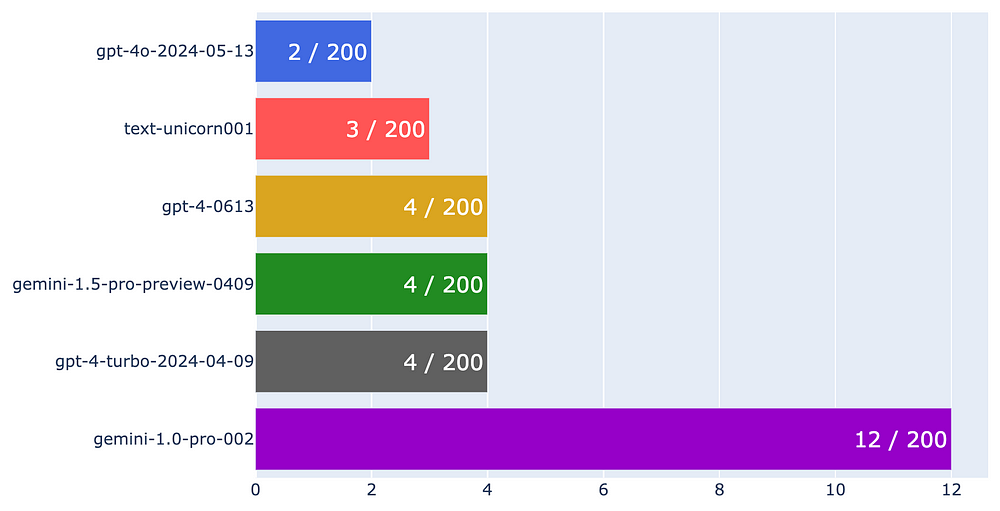
As we can derive from the graph, GPT-4o has the lowest error rate of all the models with only 2 mistakes.
We can also see that Palm 2 Unicorn, GPT-4, and Gemini 1.5 were close to GPT-4o — showcasing their strong performance.
Interestingly, GPT-4 Turbo performs similarly to GPT-4–0613. Check out OpenAI’s model page for additional info on their models.
Lastly, Gemini 1.0 is lagging behind, which should be expected given its price range.
Conclusion
This analysis using a uniquely crafted English dataset reveals insights into the state-of-the-art capabilities of these advanced language models.
GPT-4o, OpenAI’s latest offering, stands out with the lowest error rate among the tested models, which affirms OpenAI’s claims regarding its performance.

